-
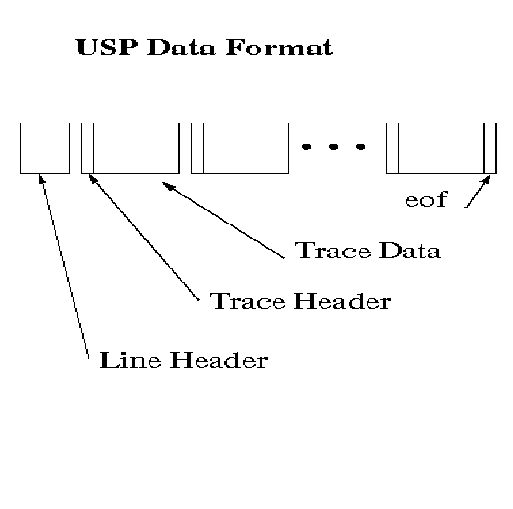
The power of USP is related to interaction with UNIX, the ability to do networked (multi-cpu) processing and fast disk addressing within large data volumes. The last two strengths relate directly to the data format used within the system. All information required to describe the data is contained in the data stream which makes network processing efficient. A USP dataset consists of a line header followed by traces and terminated by an End Of File (EOF). In the line header is enough information to locate any element of the dataset on disk or in a pipe stream.
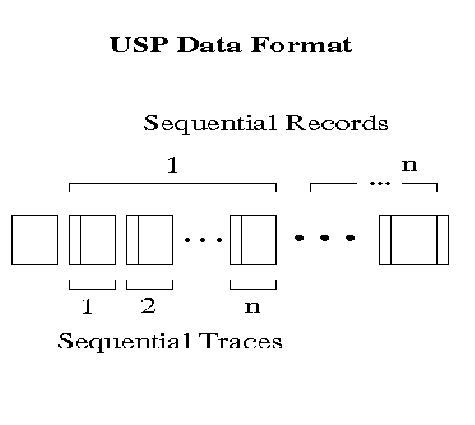
Contained therein are the number of records in the dataset (NumRec), the number of traces in a given record (NumTrc) and the number of data samples in a given trace (NumSmp). With this information it is possible to move a disk pointer in a fraction of a millisecond to any position within a disk file. This process introduces the concept of sequential records, traces and samples . Historically, one has positioned ones self, mentally, within the data in terms of a stacking diagram used to process the line. That is, in terms of shot point, depth index, group location or the like (not sequential record, trace and sample). For this reason people new to the USP processing community often become confused between the sequential location of a trace and the indexing stored in that trace's header.
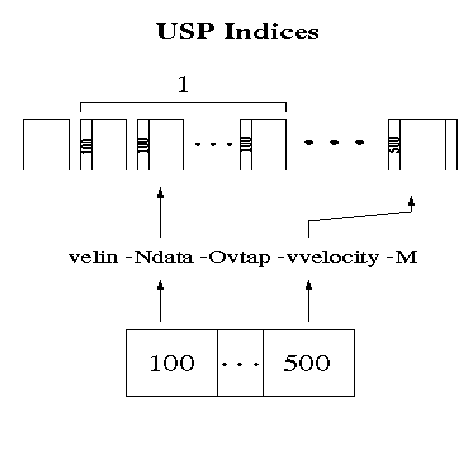
Consider a dataset containing shot points 100 through 500 (a total of 401 records) with 120 traces per record and 1000 samples per trace. Here shot record 100 is located at sequential record 1 and shot record 500 is sequential record 401. To relate this dataset to a set of velocity parameters derived and indexed at those shot locations one would make use of the index information used in the trace headers. For instance when the line was prepared for processing a prepping routine would have been run to load the appropriate geographic location information into the headers (maip, laip, pr3d, line, pattern, source or whatever). The velocity routine, velin, looks in the user defined trace header location for the appropriate index and interpolates from the supplied set of functions the velocity function to build at that location of the output.
To understand the benefit of such a scheme the speed with which a disk dataset can be selectively searched or for that matter sorted. In USP, data can be served off disk in any sorted order just a quickly as UNIX can copy the file. You may plot record 3000 from a 5000 record dataset just as fast as your can plot record 1. The USP routine just moves a pointer to the disk location of interest and starts stripping off data. No overhead is involved in determining from a database somewhere or from reading the trace header information to determine where in the data the pointer is currently positioned. In USP , we know where we are in terms of sequential record, trace and sample at all times.
As a processor you will have to reference both the line and trace header. In USP we reference header information using mnemonics. To get a verbose listing of the header mnemonics see the scan manual page.

{kind=link}
{kind=link}
{kind=link}